Frame bytes vs. frame file headers
When capturing frames from a network there is more information recorded into the capture file than just the bytes of each frame. If you have ever looked at the PCAP or PCAPng file format specifications you have seen that each frame has an additional frame header containing important information that wasn’t part of the frame itself.
Let’s take a look at the bytes (or octets, whatever name you prefer) of a typical frame, e.g. a TCP SYN packet:
0000 00 0d b9 21 95 18 c8 60 00 16 7c cc 08 00 45 00 ...!...`..|...E. 0010 00 34 6b 8a 40 00 80 06 00 00 c0 a8 7c 64 51 d1 .4k.@.......|dQ. 0020 b3 45 c4 60 00 50 19 00 52 e7 00 00 00 00 80 02 .E.`.P..R....... 0030 20 00 42 4a 00 00 02 04 05 b4 01 03 03 02 01 01 .BJ............ 0040 04 02 ..
Now, in my favorite hex editor the same frame looks like this when it is stored into a PCAP formatted file – you can see that the actual frame only starts at offset 0x28, which is the 9th byte in the second row (marked in a red frame to make it easy to see):
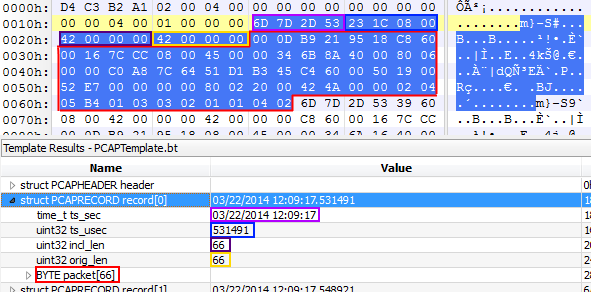
Just before the frame bytes, 16 additional bytes are used to store additional information about the frame (we’re starting simple here with the old rudimentary PCAP format; the PCAPng format has a lot more information and is far superior, but also much more complex):
- the timestamp of when the frame was captured, with 4 bytes for time and date (“ts_sec”)
- additional 4 bytes for the microseconds (“ts_usec”)
- the length of the frame as stored in the file (“incl_len”, a.k.a. “capture size”)
- the length of the frame as it really was on the network (“orig_len” a.k.a. “wire size”)
The timestamp is stored as UTC value, which may be important if you open the file on a different computer in another time zone later, as I already explained in an earlier blog post. You may wonder why there are two length values, so let’s take a look.
Hard Slicing vs. Soft Slicing
“Slicing” is what we call the process of cutting away bytes from a frame before writing it to disk, which means that only the first part of the frame is preserved. The amount of bytes that are stored depends on how the capture software was configured before starting the capture.
There are a couple of reasons why you would want to store only parts of a frame:
- you only need to see the protocol headers for troubleshooting anyway
- you need to save disk space by not storing full frames, e.g. when performing baselining
- privacy concerns force you to keep sensitive data from ending up in your capture file
Wireshark allows you to do this in the capture setup dialog (which ends up being a “-s” command line parameter pushed to dumpcap as soon as you start the capture):
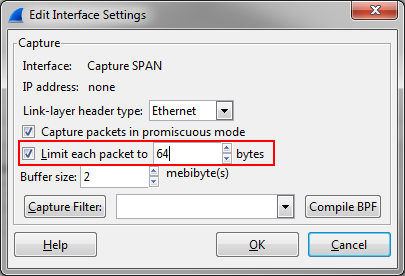
Wireshark is doing what I call “soft slicing“, which means it will only record as many bytes as you specify, but it will still keep the original frame size stored in the frame header. So if a frame has let’s say 1518 bytes Wireshark will store 64 bytes and set the value of “incl_len” to 64, but store “orig_len” as 1514 (remember, the 4 byte FCS is not stored). Here’s an example sliced to 54 bytes, while the original frame had 1514 bytes (the FCS wasn’t saved to file), as you can see in the first line:

Why 54 bytes, you ask? Ethernet header (14 bytes) plus IPv4 header (20 bytes, without options) plus TCP header (again, 20 bytes without options) equals 54 bytes – so this frame had been sliced right after the TCP header, cutting away all the payload. You can still see that the TCP payload len is dissected as being 1460. If we calculate it the other way around, 1460 bytes payload + 20 bytes TCP header + 20 bytes IP header + 14 bytes Ethernet header = 1514 bytes.
“Soft slicing” is the “good” way of cutting bytes away, because it will retain the information about the original frame size, even though you can’t look at all of it anymore. In contrast, “Hard slicing” is the “bad” way of cutting away bytes, where you not only lose the content but also the original length information. So why is that so bad?
Well, lets look at an example that I captured on a VMware SPAN session on a Distributed vSwitch with a slice size (“Mirrored packet length”) of 64 bytes configured like this (if this dialog looks strange to you: it’s the web client UI):
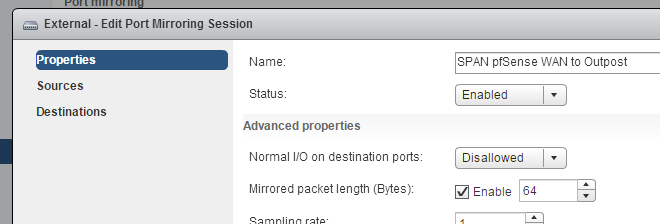
This is an example frame that is typical for a capture setup doing hard slicing:
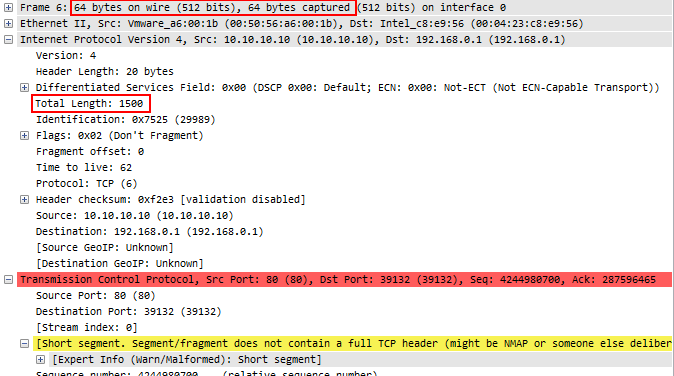
The frame header says “64 bytes on wire”, which is incorrect, while “64 bytes captured” is the truth. You can see in the IP “Total Length” field that the frame was much larger: 1518 bytes in total (or 1514, if we leave out FCS). At least the Wireshark TCP expert can still track sequence numbers as long as the IP length is correct and doesn’t care about the frame size specified in the frame file header:
![]()
As you can see there is no “segment not captured” message indicating that something is missing in the screenshot above. But all statistics will be wrong when it comes to anything that is related to frame size, so e.g. you can’t do throughput calculations.
Sometimes, it gets worse…
Hard slicing can even get worse if a tool does not handle the IP total length value carefully when cutting bytes away, or when it doesn’t want to. Let’s say we have a capture file like this (ignore the TCP checksum errors; they’re in there because I did a local capture):

Now let’s say for privacy reasons we only want to remove all TCP payloads from the packets, and keep only the headers intact. You could do that with bittwiste, e.g. by running a command like this (the -L parameter specifies the layer after which to cut):
bittwiste -I "HTTP Sample.pcap" -O "HTTP Sample-hardsliced.pcap" -L 4
When you open the new file in Wireshark, it will look like this:

Remember, all I did was telling bittwiste to remove everything after layer 4. That gives us a typical frame size of 54 for a TCP packet without options (14 bytes Ethernet header, 20 bytes IPv4 header, 20 bytes TCP header). So why is the TCP expert of Wireshark going crazy now?
Well, if we look at frame 6, which had 1514 bytes in the unmodified file, it now looks like this:
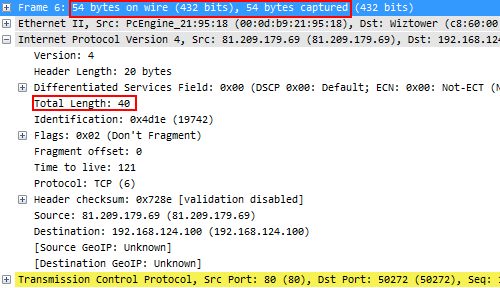
It’s easy to see that bittwiste not only reduced both “bytes on the wire” and “bytes captured” to 54, but it also wrote an IP “Total Length” of 40, which completely excludes the payload bytes. And that means that the Wireshark TCP expert now thinks that the segments are shorter than what the TCP sequence numbers indicate. Which means there seems to be packet loss. This is actually one of the things that drove me crazy when sanitizing files with bittwiste and had me create TraceWrangler. In defense of bittwiste I have to add that it is not designed as a sanitization tool – instead, it was created to modify packets for replaying them, so it makes sense if the packet in itself stays consistent.
{kind=link}
By the way, you can also use editcap to do soft slicing, but the drawback compared to bittwiste is that editcap cannot cut exactly after specific headers – it always cuts at a hard offset which also has to be the same for all frames. This is what I’d call “static soft slicing”, because it always cuts at the same offset. So if a TCP header has plenty of options they may get cut in half if you specify 64 bytes or even less. Bittwiste and TraceWrangler can do “adaptive slicing”, which requires the frames to be parsed first to see where the protocol headers end. Bittwiste does “adaptive hard slicing” (which, as we’ve seen, is not a good idea when sanitizing frames). TraceWrangler can do either “adaptive soft slicing” or “static soft slicing”, or both at the same time depending on each frame.
External slicing
“External slicing” means that the cutting is performed on a device that doesn’t actually record the frame. In most cases this means that a much shorter frame is received by the actual capture device which doesn’t even know it was reduced in size. Which means that the capture device will record the frame with the short size as both capture size and wire size, which means it’s “hard sliced”.
The VMware example above is a case where the slicing is done on the switch (even if it’s a virtual one), so when Wireshark receives the frame it has to assume that it was actually only 64 bytes long, because that’s what arrived. This is a problem that always comes up when the slicing isn’t done on the recording device (e.g. the PC running Wireshark). Intelligent TAPs can cut frames at certain offsets, but when the resulting frame is passed on it is actually shorter than it had been before:
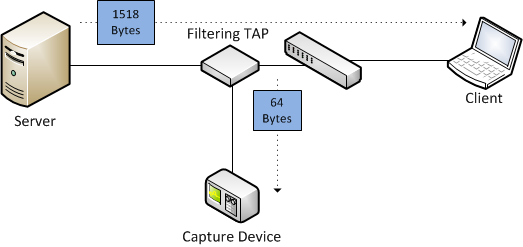
The problem is, that the filtering TAP has to forward a valid frame, but it cannot just send an additional parameter saying “dear capture device, the next frame I sent was sliced from 1518 to 64 bytes, so please record both sizes correctly”, at least as long as it is forwarding the frame via Ethernet (which is the most common situation). It can only forward the shorter frame. Keep in mind: the total frame size is not written down as bytes anywhere in the frame, at least not for Ethernet (and I know of no layer 2 protocol that does, but I’m sure some do). The length of the frame is something the capture device determines when it receives it, but when it is already arrives shorter than it originally was it can’t know what the size had been on the wire.
Fixing the frame wire length problem
TAP vendors offering intelligent Ethernet tapping devices are most likely painfully aware that it is a problem if the TAP does not have a way to tell the capture device that slicing occurred and how large the wire size was. A possible workaround could be for the TAP to add a few bytes to the end of the frame, containing information about the original size. Some already do that to transmit port numbers (if the TAP has multiple links it captures frames from) or more accurate timestamps. The problem always is that bytes trailing the original frame bytes may be ignored by the capture device, or not interpreted correctly. Even Wireshark has to guess if something trailing a frame is information added by a TAP (if you’re interested, take a look at packet-vssmonitoring.c, created by Sake).
Another possibility to get the correct wire frame size is using TAPs that doesn’t forward the sliced frames via Ethernet. The ProfiShark USB 3 TAP can keep the original frame size if you’re using it’s native capture utility to record capture files.
You can also deduct the correct length from protocols like IPv4 or IPv6 (unless it was cut with a tool like bittwiste, which adjusts the payload length). If we look at the IPv4 example again, the “Total Length” field actually tells us how long the frame must have been on the wire. So with that, the frame wire size value could be easily fixed. Actually, the next release of TraceWrangler will have an option for this when running an “Edit” task (now already available at the new automated build section):
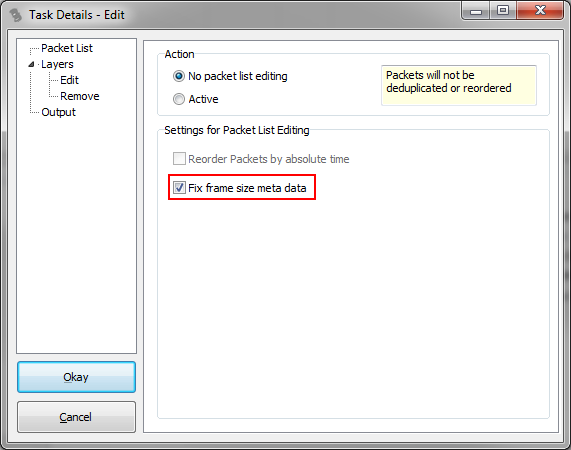
To do that, TraceWrangler decodes each frame where capture and wire size are the same. Then it checks if there is an IPv4 or IPv6 header, and calculates the original wire size. Before writing the frame back to disk, the correct wire size is set in the meta information of that frame if it was too small.
Glossary
Wire size size of the frame on the actual wire / air Capture size amount of bytes kept of the frame in the capture file. Cannot exceed wire size, but can be less. Slicing cutting away bytes from a frame (meaning, "capture size" < "wire size") Hard Slicing cutting bytes and setting capture and wire size to the new (short) length Soft Slicing cutting bytes and adjusting only capture size to the new (short) length while keeping wire size intact Adaptive Slicing cutting on offsets depending on header sizes, e.g "after the TCP header" or "after the IPv6 header" Static Slicing cutting at a specific offset, regardless of frame headers External Slicing cutting is performed on a device not doing the capture. This often results in hard sliced captures.
Great article! I’m just wondering … ” there is more information recorded into the capture file than just the bytes of each frame” and ” just before the frame bytes, 16 additional bytes are used to store additional information about the frame”. Are those informations sent over the network ? Or is this just a Wireshark “interpretation”? I mean does it send the frame + this 16 additional bytes as in your example over the wire? Thank you for clearing my doubts! BR Adam
Thanks, Adam!
Those 16 additional bytes are not sent over the network, it’s created at the time when the frame is captured. It’s similar to what a modern digital camera does when taking a picture: it records all the settings of the camera (like shutter speed, GPS coordinates, etc.) – those are not part of the picture, but details about the moment it was taken. This is what network capture tools do: take notes like frame length, time of day, etc.
Cheers,
Jasper
Hello Jasper,
now everything is clear! Thank you one more time.
Best Regards
Adam
Hallo Jasper,
how can desabled this additional Bytes?
i don’t want to have it in my capture, because i use the captured Data to make some replay of the same Data.
thanks
Hello Brice,
You can’t disable those bytes, they are required to store the packets in a meaningful way. Wireshark will not display them in the byte pane though, so you can export your data without having to worry about them at all.
how to convert hex to (day ,month , year).
d y
11-Dec-16 08:43:25 62 68 8A 2D
please help me to convert the data.
Hi, that’s hard to say without knowing how it’s encoded. In epoch time it would be Sat, 19 Mar 1994 02:50:10 GMT. Where did those bytes come from? What field/protocol?
Sorry for the many years’ delay. I wrote this piece of code to get it in python :
import datetime
def truncate_and_convert_hex_timestamp_to_string(ts):
“””
Truncate hex timestamps from ERF files and return as string object.
:param ts: string rendition of hex timestamp
:type ts: str
:return: timestamp of the hex time
:rtype: str
“””
# want first 8 hex chars only
# return datetime.datetime.fromtimestamp(int(ts[:10], 0))
return datetime.datetime.fromtimestamp(int(ts[:10], 0)).strftime(“%Y-%m-%d %H:%M:%S”)