How millisecond delays may kill database performance
Mike, an old buddy of mine is one of the best database application development consultants I have ever met. We worked together for the same company for a couple of years before I got into network analysis and he started his own company. A couple of months ago I found out that there was going to be a conference in my home town where Mike was on the organization team. After a friendly banter on Twitter about him having to come to my city (Düsseldorf; which guys from Cologne like Mike don’t like ;-)) he told me that I should turn in a proposal for a talk. I said I could do that, but not on any database development topic – but maybe a generic network application performance talk might be interesting for those guys attending. So I did, and it got refused, despite Mike advocating for me. Darn.
Well, it’s a nice topic for a blog post nonetheless. So here we go.
Application developers vs. the network
In my experience, developers don’t care much about networks – it’s basically in almost all cases considered to be a close-to-zero delay link from the users desktop to the database engine on the server. Same as as the database would be running on localhost, right? And the bandwidth used by typical database application is not really that big, so even 100Mbit is often way more than enough.
Now, there are a couple of problems I often see when looking at how application developers work (and I usually ranted about that in the network analysis classes I taught):
- they have the fastest PCs/Workstations in the whole company, with tons of RAM, fast hard drives (or SSDs, these days), and multi core CPUs running at really high frequencies
- The development environment runs on the same machine with the database, making connections to localhost
Now, if an application is deployed on a customer network, these parameters almost never apply: the users have machines that are sometimes many years older than the development workstations, and run on 100MBit links in most cases. The database is located in a data center that may not even be located in the same building, but it often has 1GBit or faster back bone connectivity. As soon as the application is rolled out, users complain because it’s so slow. But how can that be?
A client with a database performance problem
I had one case a couple of years back where a client called me because his application just would not perform anymore after a environment change. He told me that:
- When everything was “okay”, the database had run on a server next to the application server (it was a multi-tier architecture, with desktop applications connecting to the application server, which in turn queried the database engine). “Okay” meaning: users did not complain THAT much. “next to” meaning, both servers were physically connected to the same switch.
- Someone decided to move the database server to a different data center, about 10 kilometers away, because there were experienced OS admins for that kind of server at that other location
- connectivity between original data center and new data center was a wireless microwave link of 34MBit, which was considered more than enough bandwidth for the amount of database traffic
Well, after the server had been moved, users complained that instead of waiting a couple of seconds for some activities they now had to wait minutes sometimes. When my customer tested the connection, it was as fast as expected, he said. Of course I was curious and asked him how he performed that test, and it was exactly what I had expected: he ran an FTP download from one data center to the other, confirming that the transfer would achieve almost 30 MBit of throughput. I told him that a test like that doesn’t help at all, because he compared a throughput based application to a transaction based application. We finally agreed I’d come to the customer site and capture some of the traffic to see what was going on.
Database communication scenarios
For demonstration purposes I decided to set up an database and take 5 minutes to write a small client application that queries some simple things. So I got myself a demo database, set up some MySQL servers and ran my demo application in various setups.What the application does is
- pull a complete list of employees
- query each of the first 10,000 employee’s salary records afterwards.
So we should see one query for the employee table in the capture, and a lot (well, 10,000) queries following the first query, asking for the salary of each employee. It’s not elegant, but it’s something I often see when looking at how database programmers code their queries. The problem with that kind of program structure is obviously that after the first request all salary requests are serialized, going back and forth between client and server. That adds 10.000 times the round trip time between the two machines as a minimum delay until all data is transferred.
Scenario 1: database running on localhost
In this scenario, my client and the database run on the same system. The problem with that kind of setup is that Wireshark can’t capture localhost traffic on Windows systems, so I had to use rawcap instead (the interface with index 2 being my localhost interface).
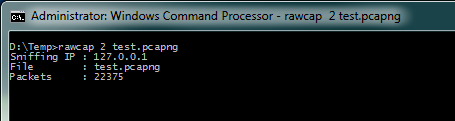
When I looked at the capture, the Initial Round Trip Time was exactly 1 millisecond. I would have expected it to be a lot less, but my guess is that the timings in localhost captures are not as precise as I thought they would be (trying to use the -f parameter to flush frames right away without buffering them first made things worse, dropping tons of frames and not helping the timings). Another symptom added to that suspicion, because I had quite a number of dropped frames in the capture (about 3.1% of all frames). Anyway, for a speed test like this the drops do not matter much.
I filtered on the actual queries by using “mysql.command==3”, which I took from the decode of the first actual query:
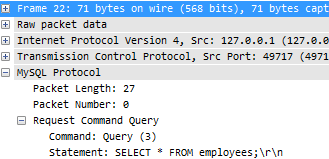
To see the query statement itself I also added a new custom column by right-clicking on the statement line and selecting “Apply as column” from the pop up menu. The filtered capture looks like this: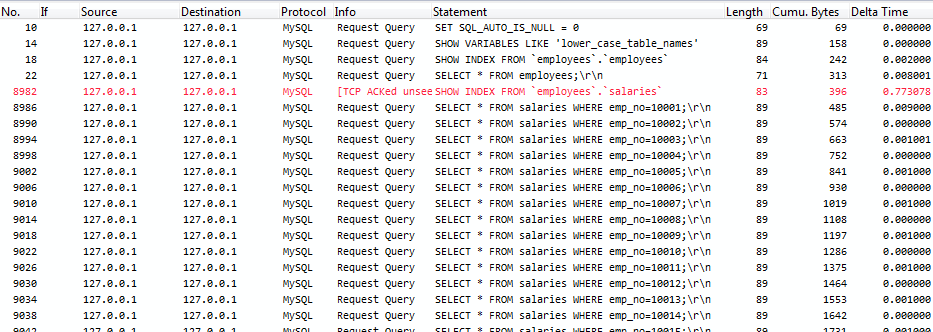 You can see in packet 8982 that a unseen packet was acknowledged; this is an ACK for a dropped frame (one of the 3.1% I already mentioned). Anyway, what is interesting here is that the “Delta Time” between requests for the salary records is between zero and one millisecond. I think that this is again caused by how the rawcap recording process works – normally, I’d expect the timings to be less digital (“0 or 1”) with more and smaller numbers in between. Let’s just say the delay between queries is what we see in worst case, which is 1 millisecond.
You can see in packet 8982 that a unseen packet was acknowledged; this is an ACK for a dropped frame (one of the 3.1% I already mentioned). Anyway, what is interesting here is that the “Delta Time” between requests for the salary records is between zero and one millisecond. I think that this is again caused by how the rawcap recording process works – normally, I’d expect the timings to be less digital (“0 or 1”) with more and smaller numbers in between. Let’s just say the delay between queries is what we see in worst case, which is 1 millisecond.
My test client (and the trace duration) both state that the whole process took about 5.7 seconds from start to finish.
Scenario 2: local area network
As a next step, I reproduced the setup of client and server being on different machines, but connected to the same switch. Interesting fact: the TCP initial RTT was 0.389 milliseconds this time (a lot faster than the localhost iRTT), and no dropped frames at all – I guess rawcap has some issues capturing all traffic with precise timings on localhost. It’s still a good tool to have though, because there is no other way to grab localhost packets on Windows.
Anyway, here’s what the Wireshark capture looks like, filtered on the queries again: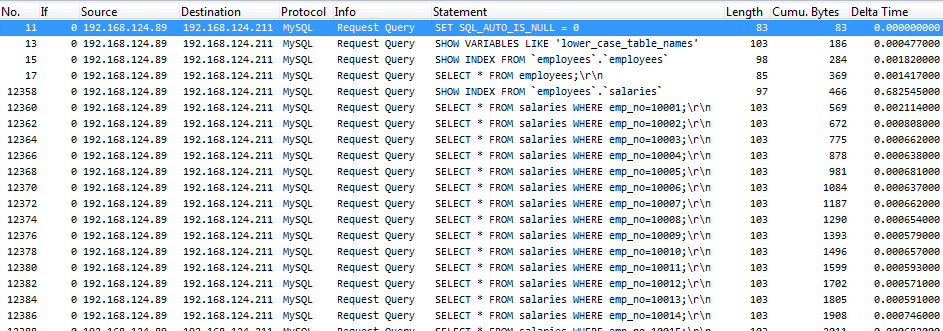
The delay between the salary queries are about 800 microseconds in worst case, and the whole process took about 6.7 seconds, so only about a second more than localhost. Not too bad, even though waiting for almost 7 seconds for a result from a database can be painful – so it’s not exactly good, either, but that is caused by the way the program is coded.
Scenario 3: remote data center
For this scenario I set up the database on a server in a data center about 10-15 km away, with the lowest link being 32MBit between client and server. So it’s pretty close to that customer situation a couple of years ago.
I could tell right away that the story was completely different this time, since it took ages until the client program finished the queries. Looking at the trace, the initial RTT was about 12.9 milliseconds, which is not bad for a connection like that, going through a couple of routers and switches. The connection also had a couple of lost packets that had to be retransmitted, which is always to be expected to some extent on connections that leave the local network.
Here’s the capture:
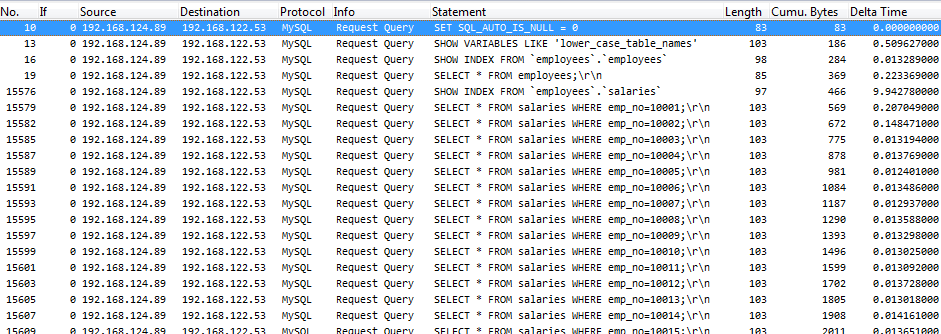
This time, the delay between queries is about 15ms, which is more than 15 times more than the local area network test. 10.000 queries times 15 ms are 150 seconds. Guess what? The tool (and total trace duration) both reported 156 seconds for the whole process, which is about 2.5 minutes.
Summary
It is important to keep an eye on latency if a database (or any other transaction oriented application) is deployed, because even a delay of a couple of milliseconds can add up dramatically based on how queries are coded. There’s two solutions to a situation like that:
- move the clients and servers closer to each other to reduce latency
- replace old components with newer devices with less latency (but that only makes sense if the difference between old and new is significant)
- write more elegant code that does not blindly query large batches of information it may not even need – or design the database in a way that important things can be pulled in one request.
Back to my client: the problem was that the application could not be rewritten to pull data more efficiently over that kind of distance. In the end, the server was in fact moved all the way back to where it had been, and things got back to normal right away.
Jasper,
I belive that one of the greatest factors effecting application performance today in our high BW networks is latency, and people, application designers just do not understand or take this into account.
My war story was similar where someone, not a system designer or architect, decided that it would be more cost effective to move a web gateway from out of the regions, Asia Pacific and Europe and install it in the US. The backend databases were left in region due to not having the capacity to host them with the Web GW.
So a user in Australia subitting a request to the DB connected to the US web site and the request was sent by the app server to the DB in Australia. The results were send back to the US for the app server to send them back the AU and the user.
This took a not great but usable application to something that did not work.
When I pointed out that the US did not have an issue due to there being only 1ms between the app servers and the DB server, they were in the same data centre, Europe went from about 60ms loop delay to 110ms and AP went from about 70ms to 300ms.
It came down to the US could run 1000 requests/sec
Europe could run 9 requests/sec
AP could only run 3 requests/sec.
As the latency could not be changed, except as you said to move the GW servers back, this we were told was not an option. What we did was to increase the data throughput to see if we could reduce the time taken by the app. We tuned MQ, did I mention that they were using MQ messaging between the app servers the DB server. We increased the number of messages per batch from the default of 50 to 100, turned on channel compression – always there but not used often, this reduced the amount of traffic acorss the network by over 70%, and increased the send/receive TCP buffers at both ends.
We increased the throughput from 470Kbps to 6.3Mbps and made the application usable again.
Keep up the good work, until we find a way to increase the speed of light we will always have latency issues.
Thanks, Chris! My favorite reply to those trying to improve latency with higher bandwidth (e.g. going from 100MBit/s to 1GBit/s) is always “hm, do you think the light is going to travel faster when you do that?” 🙂
I wrote a very simple python script that reports back the latency to MySQL servers. It runs a simple “SELECT 1;” 1,000 times and reports back the execution time. From it I was able to determine that moving my app server to a DC further away from the DB instance would result in a 20X increase in MySQL latency. Just run it in each of the locations you want to check and compare the results.
https://gist.github.com/stickystyle/8cebde204781b7d27c90
Great, thanks Ryan! Combined with packet captures this may provide even more insight on what is happening 😉
Over the years I’ve often seen large SQL queries that return thousands of rows of data, but the code asks for only 1, 5, 10 or 50 at a time. I only recently discovered that the Oracle JDBC driver has a default of just 10 rows.
I recently analysed an application that retrieved 20,000 rows at just 10 times, resulting in 2,000 round trips – which at 5 ms each added up to 10 seconds “wasted” for the user. Every additional millisecond of RTT would add 2 seconds.
I wonder how someone at Oracle once decided that 10 was a good number to use as a default?
I’ve seen other frameworks defaulting to 50 rows, which is not bad, either. 10 seems really low, but maybe that’s the average number of lines visible in a typical application list view. I guess Oracle has statistics about what typical applications look like and selected that number based on statistics. Or they’re just Oracle and decide that 10 is best 🙂
The product that my company makes (www.heimdalldata.com) has an option to induce delays into the database queries as a way to help evaluate the impact that adding latency will introduce in a product. In addition, the fastest query is one that is never made–one of the main features of the product is to analyze the database queries, and cache queries that are redundant without code changes. Frameworks like Hibernate have a cache as well, but they often leave plenty of room to improve without impacting data integrity. It isn’t unusual to find that over half the queries that are made are simply unnecessary.
Code that unintelligently makes N queries of the database after you do an initial select is horrible.
Solution 1: use a join. Assuming an index on salaries.emp_no, this should be perfectly fast for 10k rows. select * from employees e inner join salaries s on (e.id=s.emp_no)
Solution 2: use an “in” query. So you need two queries, fine. First you get all of the data from the employees table. In a loop in your code, extract just the employee.id fields into a list/array. Then run this query: select * from salaries where emp_no in (1,2,3,4,5…,n)
Either solution reduces your total number of queries down to 2 or even 1 query, rather than 1 + N queries based on the results of the first.
It’s head-hurting to see such bad code in production.
Yes, you’re absolutely right. Unfortunately I have seen such code in production quite a few number of times 😉
Hello Jasper
Another great post, I am trying to read all your blog post in my spare time, it will take me a while 🙂
I particularly like the way you go about explaining the subject of your blogs, easy to follow and informative
Thanks
Ernie
Does anyone have a solution for less than 5 ms latency between 2 DCs some 1000 kms apart – SQL applications etc.
That would be physically impossible I think. Even if you have a straight line between the 2 DCs (no routers or other devices that add latency), the sheer distance of 1000 kilometers will cost you the 5ms for transport in the cable itself. So there is no solution other than moving the data centers closer to each other, unfortunately.
There is a good article about that here: http://www.lovemytool.com/blog/2013/08/its-the-speed-of-light-dudeby-dc-palter.html