
Programmable ASICs in Cisco Switches
I know what a Cisco switch is. I know what an ASIC is – a processor designed for a special purpose that it can do it’s job faster than a generic purpose processor running the job in software. What I didn’t know is that it was also possible to build programmable ASICs.
A few weeks ago I was invited to take part as a delegate at Tech Field Day Extra at Cisco Live 2017 in Berlin. Having been asked to join TFD came as a pleasant surprise to me, and since it was my first event of that kind, I didn’t really know what to expect. I’ve seen a few videos from the Riverbed event where my friend Hansang presented SDWAN though, so I knew the basic setup.
Introduction
One of the sessions that were presented covered the programmable ASICs Cisco uses in their 3850 series of Catalyst switches. The problem with switching (or any kind of network frame/packet processing) usually is that there are basically two type of tasks you perform: those that you can do extremely fast, and those that are relatively slow. The only reason why today’s networks are as fast as they are is that they offload the most common tasks to specialized hardware, e.g. forwarding/routing frames from one network port to another. Of course there are certain prerequisites that must be met before things can be done fast, e.g. you need to know what destination MAC is reachable on what network port. But once you know that a specific MAC address is on that port, pushing packets that way is easy. And that’s what ASICs do – perform tasks in hardware fast, e.g. MAC lookup, IP address lookup, and others:
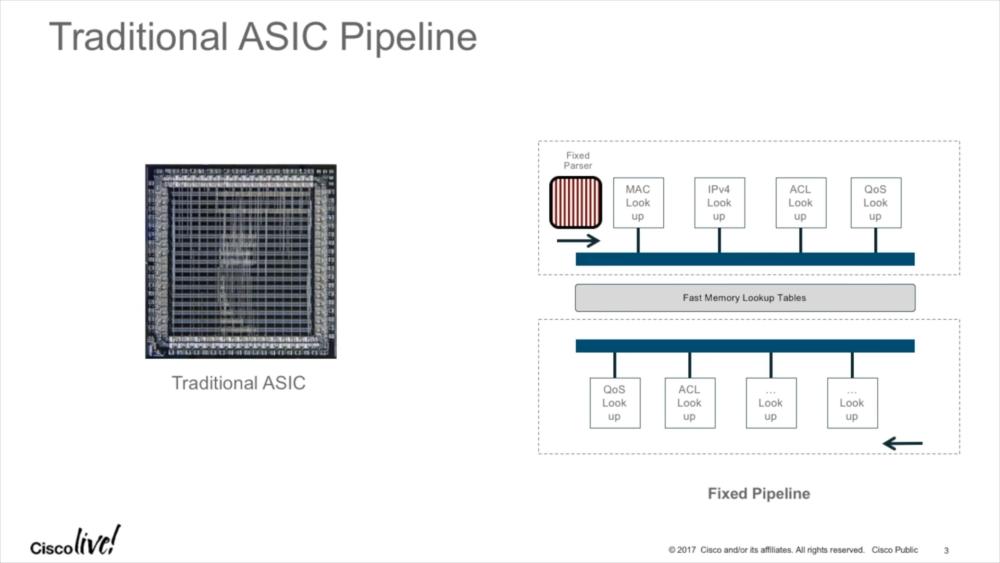
Figure 1 – Traditional ASIC Pipeline
Tasks that usually involve the switch CPU are more complex or “unexpected”, e.g. when you ping the switch management IP – reacting to that ICMP echo request packet is usually too complex to do in hardware, so a general purpose CPU running the operating system takes over. This, by the way, is/was a common attack vector against infrastructure devices, recently seen in the “Black Nurse” attack (wow, so many fancy names these days for attacks…) – if you can get a switch, router or firewall (or any other network device forwarding packets) to involve the CPU in processing all of your packets, it will most likely bring down the CPU of that device. If you ever wondered why someone configure routers not to create “ICMP destination unreachable – Fragmentation needed” for packets being larger than the next hop MTU, that’s why – it protects against CPU resource exhaustion.
Programmable ASICs
The problem with ASICs is that once produced, you can’t really change their feature set. Every change requires going through the whole process of defining the architecture, design, synthesis, floor planing, and fabrication, so the product live cycle takes a while until a new ASIC version can be deployed (between two and four years, typically). Being able to program even a small part of an ASIC is a great advantage, allowing to perform tasks that require greater flexibility than usually possible. This becomes even more important these days since other than a few years ago tunneling protocols become more and more important – and you simply cannot replace your switches just because you need your ASIC to be able to process a new tunnel protocol header. Cisco built the “Unified Access Data Plane” (UADP) ASIC for that and other tasks, allowing encapsulation or decapsulation of packets dynamically without taking a performance hit:
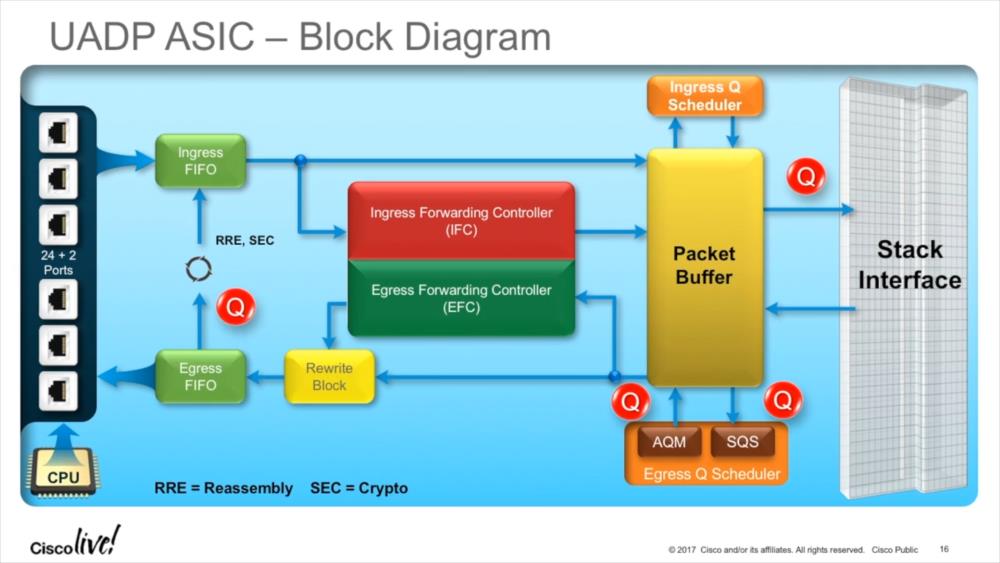
Figure 2 – Cisco UADP Block Diagram
The ASIC can also handle reassembly if necessary (which may happen if tunneled packets need to be fragmented when the additional tunnel header bytes exceed MTU), and run the reassembled frame through the process again (“Recirculation”). Recirculation adds a delay only about 0,5 microseconds to the duration of the processing, so it’s not really a significant amount of time (unless you’re concerned about nanoseconds in your line of business, of course).
The UADP ASIC can run is what Cisco calls “Micro Engines”, which process frames really fast for various aspects:

Figure 3 – UADP MicroEngines
Especially interesting for me are the encryption and Netflow Micro Engines. MACSEC Encryption is becoming more and more important to protect links against snooping or other attacks, providing security for layer 2 connectivity, and the latest ASIC version 1.1 supports 256 bit AES now (previous 128 bit), for up to 40Gbit throughputs:

Figure 4 – UADP ASIC Second Generation Features
Netflow support in hardware
Netflow is an interesting technology from my point of view. Of course I prefer full packet captures whenever possible, but Netflow has one advantage that is hard to beat: the amount of data is orders of magnitude smaller, because only meta data is kept and stored. Most people probably think about Netflow as a tool for network operation centers, but it’s getting more and more important in security operation centers as well. Especially in incident response situations a typical question is “hm, someone breached that server. Can someone tell me if the intruder tried to move laterally, when and where to? And was it successful?” – and that is something you usually can’t answer without historical NetFlow records (keep in mind: many breaches are detected days/weeks/months after the fact).
The problem with Netflow is this: whenever I suggest collecting NetFlow data, network admins often aren’t happy. The reason for that is that there is a performance impact if you’re collecting NetFlow data on a switch, router or other device, and that impact can be so bad that it hurts the quality of the normal functionality of switching/routing/filtering packets. The most common way around that is to add dedicated NetFlow collection probes, but they have disadvantages, too: they cost additional money, you need to SPAN traffic to them (which comes with a cost as well, and permanently blocks troubleshooting capabilities), and depending on what you SPAN they may not see everything happening on the monitored device.
Being able to collect NetFlow data in hardware without speed penalties is a huge plus from my point of view – so as soon as the new switches find their way into the data centers, there’s less excuses for not doing NetFlow collection 🙂
Disclosure
This post is a part of my Tech Field Day post series. I was invited to this event by Gestalt IT. Gestalt IT covered travel, accommodation and food during the event duration. I did not receive any compensation for participation in this event, and I am also not obliged to blog or produce any kind of content.
Any tweets, blog articles or any other form of content I may produce are the exclusive product of my interest in technology and my will to share information with my industry peers. I will commit to share only my own point of view and analysis of the products and technologies I will be seeing/listening about during this event.
Oh, and thanks to my fellow delegate Max Mortillaro for letting me steal his Disclosure paragraph 🙂
Thank you for sharing this! One question, what is the difference between this ASIC and an Field Programmable Gate Array? Is there something different about its construction that allows it to be classified as an ASIC instead of an FPGA?
I’m not that deep into the specifics I have to admit, but in the end, ASICs are cheaper if mass produced since they can pack their logic into smaller packages. Design costs are higher than with FPGAs, so for small batches, FPGAs would be the right choice I think.
The difference is, in an FPGA chip you can program any arbitrary logic you want (it has to fit on the die though), while most ASICs are set in their ways so to say. A packet is buffered in, a CAM/TCAM lookup is done, the reference to SRAM is followed to modify the packet, the packet is buffered out.
But even with that in mind, if you look closely at the logs when you do a major IOS update on a switch, you sometimes can see that during the first boot it updates ASIC’s firmware (and it takes quite a while). So there might also be a microcontroller inside with some common instruction set plus some memory for programming.
With UADP, it looks like Cisco’s engineers put together an ASIC bundled with FPGA, so wirespeed features can be added after die production. That’s reasonable, given how much time it takes to create a new ASIC to add these features.
Suddenly, your 3850 has MPLS support after last Falls’ update.
(just like your Tesla’s clearance is 4cm higher one morning;-) )
I think it was just a matter of PR convenience for Cisco to call the UADP an ASIC while it definitely packs more than most ASICs before it. Because people expect an ASIC at the core of a switch, it is easier to call it an ASIC.
For as far all we know, there might be a few dozen CUDA cores on that die as well. For deep packet inspection or whatever (I have no way of knowing it but it’s fun to think about).
That is kind of what I was thinking, but couldn’t articulate anywhere near as well as you did so thank you!
Hey Jasper, I was thinking why don’t you do some videos about packet capturing., that would be cool to have some video explanations.
Hi Dom,
I was thinking about doing videos as well, but haven’t gotten around to it yet. But it’s something I’m considering doing in the future.
Hello every one, please help me
as i am looking for ASIC on which i could program…
is it possible to add custom switch port security mode like hybrid as their are already 3 defined modes, shutdown, restrict and protect
i need to simulate that function for my thesis
thanks in advance
I’m not that familiar with ASIC programming so I have to say I don’t know. If you can, follow https://twitter.com/m_a_imam on Twitter and ask him about it?
Hello ,
Is cisco switch 9500 capable allows modifying and programming the forwarding plane (P4 language).
Please advice and thanks for your time!!
Unfortunately I have no 9500 switch and I am also not sure if the forwarding plane can be programmed at all. Maybe you can ask https://twitter.com/m_a_imam for details?
Thanks !
hi,
great article. a statement i found puzzling is when you say a ASIC is a processor in hardware. ASIC is just a logic circuit(a network of or,and,not gates) that perform a specific function(in this case frame forwarding). they are not processors(CPU). they are faster than a CPU because the CPU because they don’t go through instruction circles to perform a task. Before this function was performed by CPUs(went throught fetch,decode,execute circles). by implementing the functionality using logic gates, it seems the process has been speeded up(official statement says by 10 of milli seconds).
Hi, thanks for the comment! I get your point that ASICs are quite different from all-purpose CPUs, but does that make them a non-“processing unit”? They are processing data, right? CPU for me just means that this is something that does in/out processing of data, and that’s what an ASIC does, too? Where do we draw the line – since CPUs are logic circuits as well, just all-purpose and not specific for something?