TCP Analysis and the Five-Tuple
The TCP expert of Wireshark is doing a pretty good job at pinpointing problems, helping analysts to find the packets where things go wrong. Unfortunately, there are some things that can throw the expert off pretty badly, which can fool inexperienced analysts in believing that there are big problems on the network. I did a talk about some of those problems at Sharkfest 2013 called “Top 5 False Positives”, and this post will be about on of them: Duplicate packets.
The Five-Tuple
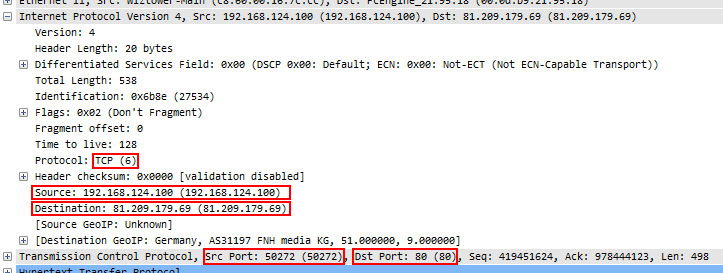
Figure 1: 5 Tuple example
The first thing that has to happen when Wireshark crunches through a ton of packets is to determine which protocol and conversation each packet belongs to. It does that by constructing the so-called “Five-Tuple” (or 5-tuple) from the packet it currently looks at, which contains the source IP, source port, destination IP, destination port, and the layer 4 protocol. An example would be “192.168.124.100/50272/81.209.179.69/80/6” for a packet coming from port 50272 of IP 192.168.124.100, going to port 80 of IP 81.209.179.69, using IP protocol 6, which is TCP:
The same IP and port combination with IP protocol 17 would indicate a UDP conversation. UDP and TCP are the most common protocols the tuple is available for, while you can’t build it for ICMP packets – simply because ICMP does not use ports, so you’d be stuck with a “3-tuple” 😉
Tracking TCP Conversation behavior
After the 5-tuple for a TCP conversation was determined, there’s two possible ways to continue (reduced to a very simple process; in reality the process is much more complex in its details):
- there is no existing conversation with the same 5-tuple, so this is the first packet of a new conversation detected in the trace. A new entry is added to the conversation list and its TCP state recorded
- a matching entry in the conversation list exists, so we can analyze the new packet in relation to the existing state of the TCP conversation
One of the most important things to look at is the sequence number in relation to the sequence number of the previous packet from the same node. For each packet the “Next Expected Sequence Number” is calculated, which you can see in Wireshark as well (as long as there is TCP payload in the packet, because otherwise, the sequence number doesn’t change):
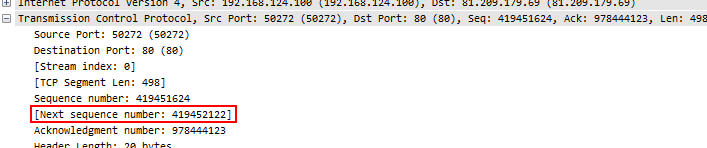
Figure 2: TCP Next Expected Sequence Number
To verify, Sequence number 4194561624 plus 498 bytes of TCP payload equals 419452122. So when the next packet of this conversation is found, it must have a sequence number of 419452122, otherwise something is wrong (Wireshark Expert messages in quotes):
- the sequence is lower than expected, meaning that this is a late (“out-of-order”) or retransmitted packet (“Retransmission”/”Fast Retransmission”). The difference is basically in the time of how late the packet arrives – a retransmission cannot arrive earlier than the duration of one Round Trip Time after packet loss was signaled by the receiver. If the new packet is arriving significantly faster, it’s an out-of-order. The difference between a “Retransmission” and a “Fast Retransmission” is in the way that packet loss is signaled or detected. Check out Chris’ post at LoveMyTool about the various flavors.
- the sequence is higher than expected, meaning that at least one TCP segment is missing (“previous segment not captured”), either because it was really lost in transmission, or simply not captured because the capture device wasn’t placed correctly or the write performance was too bad.
“Throwing off” the TCP expert
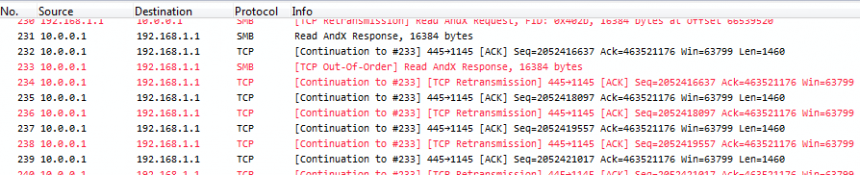
Since the TCP expert matches packets to conversations based on the 5-tuple, certain trace files can turn into a mess of TCP symptoms that are nothing but false positives for the biggest part of them. The problem in those cases is that the trace file contains the same TCP segment twice (or even more times), usually caused by the way the capture was performed. One of the most common capture problems are true duplicate packets – packets, that were captured multiple times in a SPAN port setup.
SPAN trouble
Imagine you want to do a capture of two servers that multiple clients connect to, so you configure a SPAN session, e.g. like this:
Switch(config)#monitor session 1 source interface gigabitEthernet 1/10 both Switch(config)#monitor session 1 source interface gigabitEthernet 1/11 both Switch(config)#monitor session 1 destination interface gigabitEthernet 1/24
When a client talks to a server on port 10 or 11 there is no problem. But when – for any reason – the servers themselves talk to each other, you get the same packet twice: once when it enters the switch on port 10, and the second time when it exits on port 11 (or vice versa, of course):
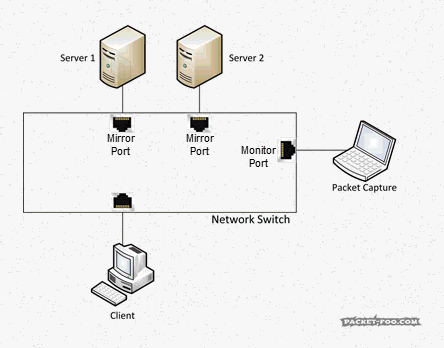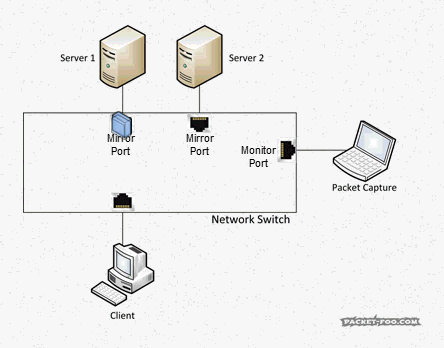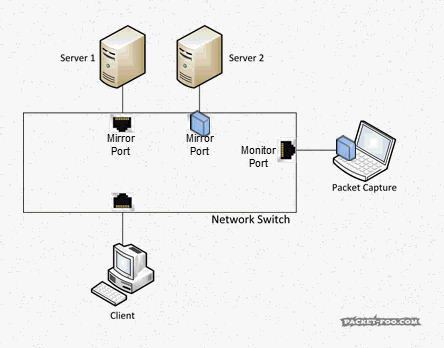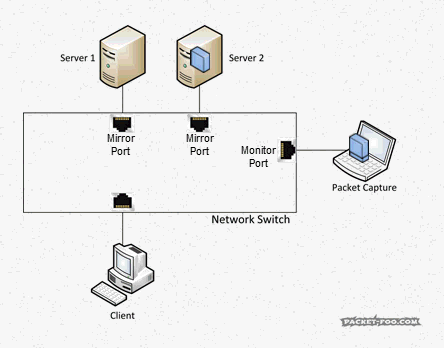
Figure 3: SPAN session resulting in duplicates
This is what Wireshark will show for a trace capture that way if duplicates happen:
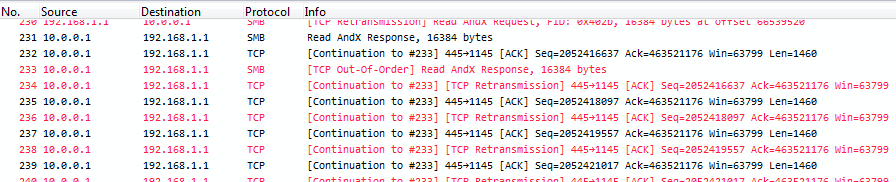
Figure 4: SPAN duplicates
Take a look at the sequence numbers, and you’ll see that each packet is seen twice – and the TCP expert gets crazy, because it thinks it’s seeing tons of retransmissions, or (depending on the capture) “Duplicate ACKs” when acknowledgement packets get duplicated. Now, the problem is that with a of capture setup like seen above there is simply no way to avoid duplicates. And the second problem is, you can’t filter away the second occurrence of each packet with a display filter in Wireshark, because the filter needs to find something to tell the two copies apart. Which cannot work, because they’re identical down to the last bit. Also, you cannot do the SPAN session in another way in most cases, because you need both directions of both ports for the normal client communication. Sometimes you can try a trick setup like only monitoring the “receive” directions of a SPANned VLAN – e.g. if you only capture incoming packets for the VLAN, you’ll just get it once, but that only works for VLAN captures, not multiple ports.
Fighting true duplicates
Fortunately, there’s help to get rid of the true duplicates: you can use the command line tool “editcap” to remove duplicates from trace files. Editcap is installed together with Wireshark, and a typical application would look like this:
D:\Traces\blog>editcap -d -D 50 duplicates.pcapng no-duplicates.pcapng 15238 packets seen, 7570 packets skipped with duplicate window of 50 packets.
The parameter “-D 50” has editcap compare a history window of 50 frames to see if they’re exactly the same as the current frame. If there’s a match, the current frame is discarded. As you can see, 7570 packets out of 15238 turned out to be duplicates, which is a little under 50%. After the process, the example from above looks like this:
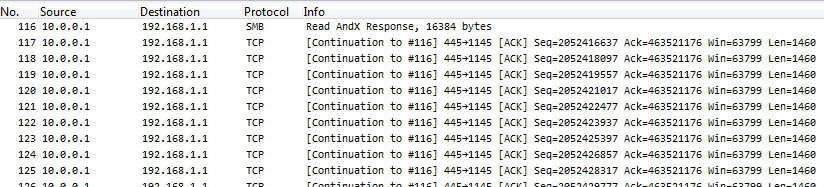
Figure 5: Deduplicated Packets
See? Same packets as before, but no more problem.
Rule of thumb: if a trace looks really really bad, with tons of TCP expert messages and no – or just a few – “previous packet not captured” symptoms, check for duplicated frames first.
Routing Trouble
Routed packets can also throw the TCP expert off, even though the packets are not exact duplicates. Here’s a sample, taken from a question on the Wireshark Q&A site (the question asked there is actually a good example of a Wireshark user being confused by the false positives):

Figure 6: Duplicate packets after routing
Again, check if there are “packet not captured” messages – because if there really is packet loss, you’ll see two symptoms: one for the lost packet, and one for the retransmission of that packet. If you only see retransmissions or duplicate ACKs, chances are high that you have duplicates in the capture.
If we take a look at the details of the packets, e.g. packet 103 and packet 104, it looks like in the following screenshots. The first is the packet before the routing process, with a TTL of 128:
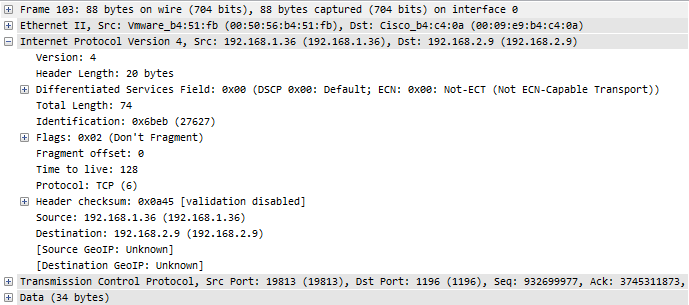
Figure 7: TTL before routing
After the routing was performed, the packet looks like this:
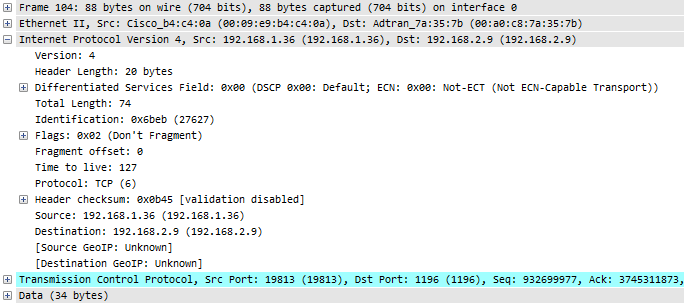
Figure 8: TTL after routing
The differences are in the Ethernet layer, because after routing the MAC addresses have to change for the new network segment – but the TCP expert doesn’t care about MAC address changes. Also, the TTL is reduced by one hop, of course – but again, the TCP expert does not look at that detail either. The rest of the packet is the same, especially the two things that the TCP expert depends upon:
- the 5-tuple is still 192.168.1.36/19813/192.168.2.9/1196/6
- the TCP layer plus the TCP payload, because it doesn’t get changed by the router
The TCP expert in Wireshark doesn’t care if the same packet is captured in different network segments, or if there are VLAN tags or tunneling involved. If it sees the same 5-tuple and the same TCP information (especially the sequence number and payload length) it will assume it’s the same packet again: “Oh, a retransmission!”.
Removing routed duplicates is actually simple: you can filter the duplicates away in Wireshark and save the remaining packets to a new file before analyzing them (Don’t forget to use “Export Specified Packets as” in the file menu, not “Save as”). I usually use the VLAN tag (if available) or the TTL for this, because it’s different – you could also focus on the Ethernet addresses, but VLAN ids/TTL is usually faster (to type into the filter field 🙂 ).
How to remove routing duplicates
To remove routing duplicates we need to determine which packets we want to keep first. Depending on how the capture was set up you might see duplicate packets coming from one IP or even both. In the example in Figure 6 you can see that only packets from 192.168.1.36 are duplicated, while those from 192.168.2.29 are not. This means that we need to determine which of the two TTLs we keep and which two TTLs we remove (two TTLs, because sender and receiver often have different values, so with duplicates, you have four TTLs). Usually, this can be done by looking at the MAC addresses and keep the packets based on matching MAC address pairs. Then, filter on the relevant TTLs and save the result:
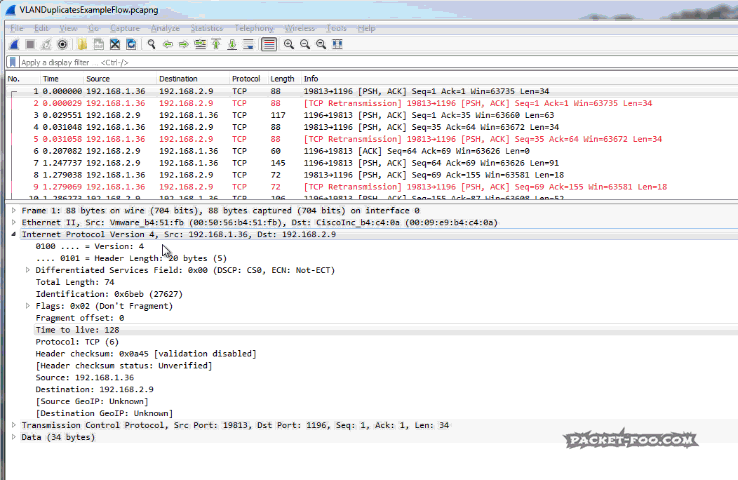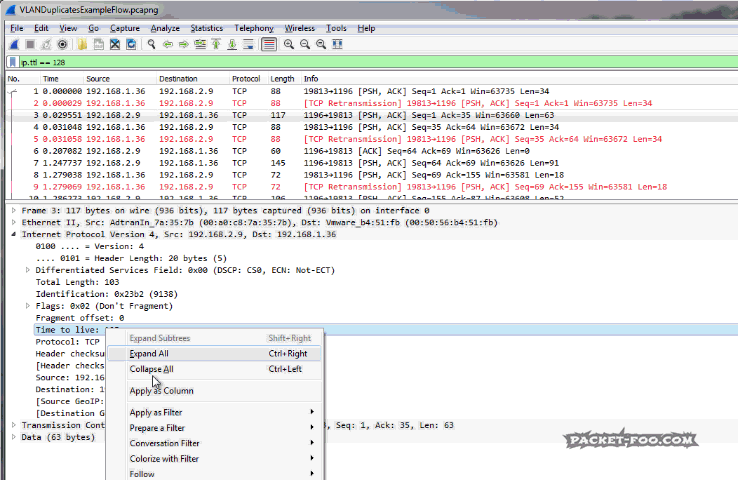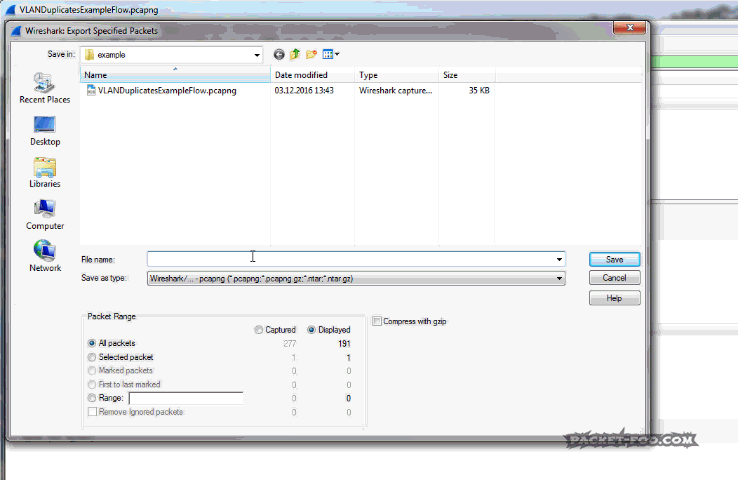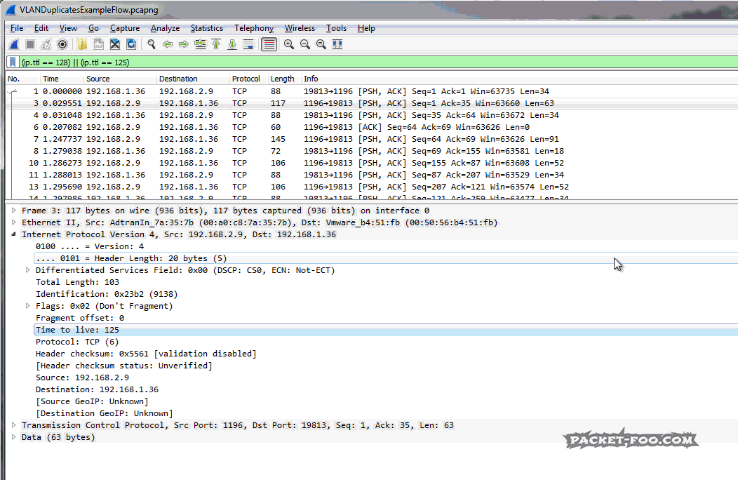
Figure 9: Deduplicating VLANs with Wireshark
Countermeasures
Now that we know why the Wireshark expert diagnoses symptoms that aren’t real, we can find a way to clean the trace up before analyzing it. The first step here is one that may not be obvious: you need to realize first that duplicates are messing with the TCP expert. For that, you should always keep an eye on the amount and attributes of retransmissions, duplicate ACKs and out-of-orders:
- check if there are more packets than usual having a TCP symptom of retransmission, out-of-order or duplicate ACK. This requires some experience with what’s normal, so do your baselines (I sound a bit like Tony here 😉 )
- verify if you also can find “Previous segment not captured” symptoms in the trace – if you don’t see those symptoms of lost segments but their retransmissions, it’s often (but not always!) just a duplicate, because you have two copies of the same segment but no “oh, something was lost” message
- if you think you have duplicates, compare the two packets by clicking on them one after the other in the packet list in rapid succession, while watching the hex view. If the bytes do not change visibly, the packets are identical.
- final check: the delta time between the two packets. Duplicates are typically less than a few microsecond apart, because they’re just two copies made on the same device at the same time. Real retransmissions need at least the full round trip time to get to the destination.
- Tip: you can also just run editcap on a trace file to see if it removes duplicates. If it does, there probably were some (“probably”, because there are some frame types identical down to the byte that aren’t duplicates, e.g. BPDU frames. But those have delta times in the seconds, not milliseconds)
If you have determined that your trace file contains duplicates, remove them before continuing. Either use editcap as demonstrated (for full frame, byte-by-byte duplicates), or filter one instance away in Wireshark for routed duplicates.
Thanks for this post, very informative!
For those who are looking for a quick filter to clean up a trace with retransmissions/duplicates:
not tcp.analysis.duplicate_ack and not tcp.analysis.retransmission
Thanks, Alberto!
I have to add that your filter expression does hide duplicate acks and retransmissions caused by duplicates, but it also filters away legitimate “problem” packets – so I do not think it is very useful.
Hello Jasper
Another great post to help me on my quest for knowledge 🙂
These post on capturing scenarios, issues and solutions really help especially for people who are starting to look at the lower levels (what’s on the wire) as opposed to just looking that the OS/App levels. So people (including me) can start to make more informed decisions on that you are really looking at, when it comes to a trace file (I will also check out your video link above)
Question:
In this post you mentioned the following:
(Don’t forget to use “Export Specified Packets as” in the file menu, not “Save as”). I usually use the TTL for this, because it’s different – you could also focus on the Ethernet addresses, but TTL is usually faster (to type into the filter field )
Can you please explain ‘how to set the TTL filter’, when choose ‘export specific packets as’ in Wireshark, I do not appear to get a filter option at this point (see graphic below)
https://1drv.ms/i/s!AqL5zUwOWToZbM7aGvYgmGeVLEw
Therefore I assume you need to enter a display filter first, if I try a display filter and use ‘Apply as filter’ in a IP TTL e.g. ip.ttl == 58 I naturally only get TTL whose TTL = 58
How do I filter to remove the duplicates as far as TTL is concerned please Jasper
Thanks again
Ernie
Thanks, for the feeback, Ernie!
You’re right, the part about filtering on TTL assumes that the reader knows more than I should have. I’ll update the blog post instead of writing it all into the comment field to make it clearer.
Thanks Jasper, much appreciated 🙂
Hello Jasper
Thanks for updating the blog to demonstrate how to filter on TTL 🙂
Ernest
“As you can see, 7570 packets out of 15238 turned out to be duplicates, which is a little over 50%.”
You meant ‘a little under 50%’ ! Otherwise this would be worrying, this would mean there were packets that occured 3x or more 🙂
You’re absolutely correct, of course – fixed now. Thanks 🙂
On a side note: I have seen traces with more than 50% duplicates, but that is rare. It requires SPANning more than 2 ports (or one ore more VLANs), and a lot of broad/multicast packets. I’ve seen it when SPANning a big VLAN on a Cisco 6500.